包過濾防火墻與代理服務器防火墻 網絡安全的雙重防線
在當今高度互聯的數字世界中,網絡安全已成為企業和個人不可忽視的核心議題。防火墻作為網絡安全架構的基石,其技術形態多樣,其中包過濾防火墻和代理服務器防火墻是兩種經典且廣泛應用的類型。它們在網絡服務中扮演著不同的角色,共同構成了多層次的安全防御體系。
一、包過濾防火墻:網絡邊界的快速哨兵
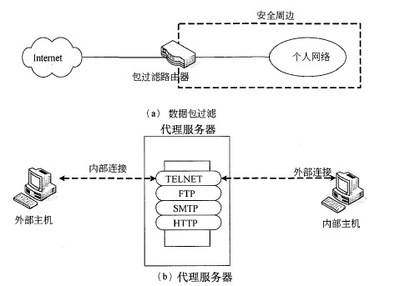
包過濾防火墻,又稱網絡層防火墻,工作在OSI模型的第三層(網絡層)和第四層(傳輸層)。它的工作原理類似于一個高效的交通檢查站,對進出網絡的數據包進行快速篩查。
工作原理:防火墻根據預先設定的規則集(訪問控制列表,ACL),檢查每個數據包的頭部信息,主要包括源IP地址、目的IP地址、端口號和協議類型(如TCP、UDP、ICMP)。例如,可以設置規則“拒絕所有從外部訪問內部網絡3389端口(遠程桌面)的連接”。
主要特點:
1. 速度快、效率高:由于只檢查包頭,處理開銷小,對網絡性能影響較低。
2. 透明性:對終端用戶和應用程序是透明的,無需特殊配置。
3. 部署簡單:通常集成在路由器、交換機或作為獨立硬件/軟件部署在網絡邊界。
局限性:
1. 安全性相對較低:無法檢查數據包的內容或有效載荷。例如,一個通過允許端口(如HTTP的80端口)進入的數據包,其內部可能包含惡意代碼,包過濾防火墻無法識別。
2. 對復雜協議支持有限:對于像FTP這樣使用動態端口的協議,配置規則可能較為復雜。
3. 無狀態檢查(早期版本):傳統的靜態包過濾不跟蹤連接狀態,容易受到IP欺騙等攻擊。現代的狀態檢測包過濾防火墻已彌補了這一缺陷,能夠跟蹤連接狀態,做出更智能的決策。
包過濾防火墻是構建第一道防線的理想選擇,適用于需要高性能、基礎網絡隔離的場景。
二、代理服務器防火墻:應用層的深度審查官
代理服務器防火墻,也稱為應用層網關,工作在OSI模型的第七層(應用層)。它充當了內部網絡客戶端與外部網絡服務器之間的“中間人”。
工作原理:當內部用戶請求訪問外部資源時,請求首先被發送到代理服務器。代理服務器代表用戶向外部服務器發起連接,接收響應,并在進行安全檢查和分析后,再將內容轉發給內部用戶。整個過程是雙向的,外部對內部的訪問也同樣通過代理進行。
主要特點:
1. 深度內容檢查:能夠解析應用層協議(如HTTP、FTP、SMTP),檢查數據包內的實際內容,從而有效防范病毒、惡意腳本和應用層攻擊。
2. 強大的身份認證和日志記錄:可以實施嚴格的用戶級認證,并記錄詳細的訪問日志,便于審計和追溯。
3. 網絡地址轉換(NAT)與隱藏內部網絡:內部IP地址不會暴露給外部網絡,增強了隱私和安全性。
4. 內容過濾與緩存:可以過濾特定網站或內容,并緩存常用數據以提升訪問速度。
局限性:
1. 性能瓶頸:由于需要對每個數據包進行深度分析和重建,處理速度較慢,可能成為網絡吞吐量的瓶頸。
2. 配置復雜:需要為每種支持的應用協議配置單獨的代理,管理和維護成本較高。
3. 客戶端可能需要配置:用戶端有時需要手動設置代理服務器地址和端口。
代理服務器防火墻適用于對安全性要求極高、需要嚴格內容控制和應用層保護的網絡環境,如企業核心數據網絡。
三、協同作戰:現代網絡服務的綜合防護
在實際的網絡技術服務部署中,包過濾防火墻和代理服務器防火墻往往不是非此即彼的選擇,而是協同工作的關系,形成深度防御策略。
一種典型的架構是:在網絡邊界部署高性能的狀態檢測包過濾防火墻,執行初步的、粗粒度的流量過濾和訪問控制,阻擋大部分明顯的非法訪問和攻擊。在其后,針對關鍵服務器或敏感網段,部署代理服務器防火墻或下一代防火墻(融合了多種技術),進行細粒度的應用層控制、內容過濾和深度威脅檢測。
隨著技術發展,統一威脅管理(UTM)和下一代防火墻(NGFW)等產品已經融合了包過濾、狀態檢測、深度包檢測(DPI)、入侵防御系統(IPS)以及應用代理等多種功能,為用戶提供了更集成化、智能化的安全解決方案。
****
包過濾防火墻和代理服務器防火墻代表了兩種不同的安全哲學:一個追求速度和廣度,一個追求深度和精度。理解它們各自的工作原理、優勢與局限,是設計和實施有效網絡安全策略的基礎。在網絡技術服務中,根據業務的具體需求、性能要求和安全等級,靈活搭配或選用融合技術,才能構建起既堅固又高效的網絡安全長城,從容應對日益復雜的網絡威脅。
如若轉載,請注明出處:http://m.dptour.cn/product/15.html
更新時間:2026-06-19 04:57:04